
こんにちは、しらすです。
Seleniumの勉強中ということで、Yahooニュースの一覧を取得するコードを作成してみたのでブログにしたいと思います。
html形式で取得し指定個所をテキストで取得
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
info = []
"""""""""""""""
#ページをhtml形式で抜き取る
"""""""""""""""
#ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome("chromedriver.exe", options=options)
#指定のWebサイトに移動
driver.get('https://www.yahoo.co.jp/')
#ページソースの取得
html = driver.page_source
#BeautifulSoup形式で取得
soup = BeautifulSoup(html, 'lxml')
"""""""""""""""
#指定の個所の情報を取得する
"""""""""""""""
#ニュース部分を取得
ele_com = soup.find_all("li", class_ = "_3ZAjBlEYxKSjGqfpxPQv4b")
#テキストだけ抽出
for ele in ele_com:
info.append(ele.text.split())前半で「ページをhtml形式で抜き取り」、後半で「指定の個所の情報を取得する」ようなっています。それぞれについて以下で詳細を解析していきたいと思います。
ライブラリのインポート
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsスクレイピングに必要なBeautifulSoupとSeleniumのライブラリをインポートします。AnacondaをインストールしていればBeautifulSoupはすでに入っているかと思います。Seleniumは設定が必要なので、まだ設定が完了していない方はこちらを参考に設定してください。設定自体はすぐに完了します。
ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome("chromedriver.exe", options=options)こちらの設定をしておくと、スクレイピングする際にいちいちブラウザが立ち上がらずバックグラウンドで処理してくれます。ブラウザを立ち上げたい場合はこちらのオプションは不要です。
指定のWebサイトに移動し、ページソースを取得、BeautifulSoup形式に変換する
#指定のWebサイトに移動
driver.get('https://www.yahoo.co.jp/')
#ページソースの取得
html = driver.page_source
#BeautifulSoup形式で取得
soup = BeautifulSoup(html, 'lxml')指定のURLに移動してページソースをBeautifulSoup形式で取得しています。後ほどスクレイピングする際にはBeautifulSoupのライブラリを使用しますので、この処理は必須です。Seleniumの役割はページソースの取得までです。ここから先はBeautifulSoupの処理部分になります。
ニュース部分を取得
ele_com = soup.find_all("li", class_ = "_3ZAjBlEYxKSjGqfpxPQv4b")タグとクラスを指定してニュースに表示されているものを一式取得しています。
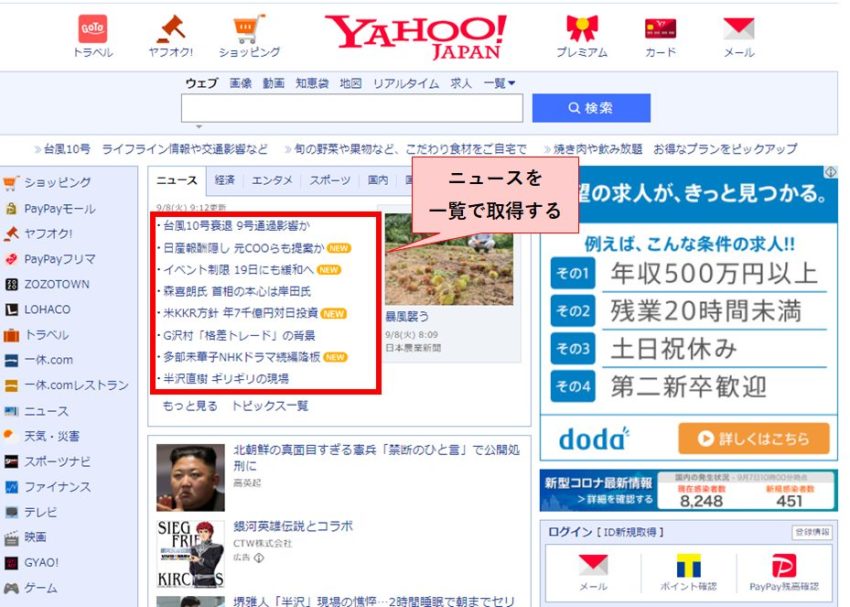
ニュース部分のタグとclassを確認してみましょう。こちらはChromeで指定のサイトを開いて確認する必要があります。chromeでスクレイピングしたいサイトを表示して、右クリック→「検証」の順にクリックすると以下のような画面が立ち上がります。右側のhtml部分をマウスオーバーすると左側のWebページの該当箇所がハイライトされるので、ニュースのリストに該当するタグを探しましょう。
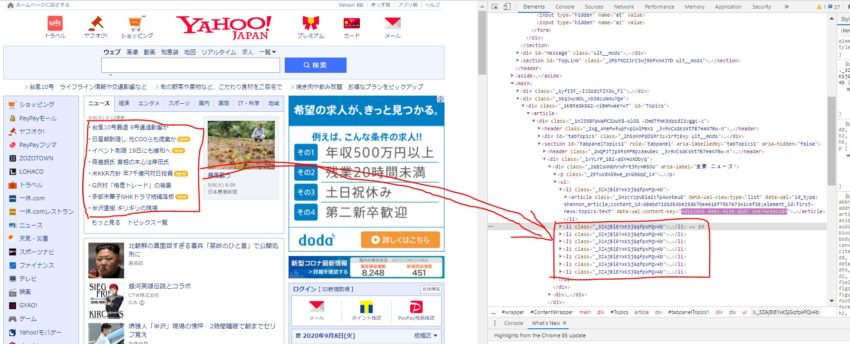
テキストだけ抽出
for ele in ele_com:
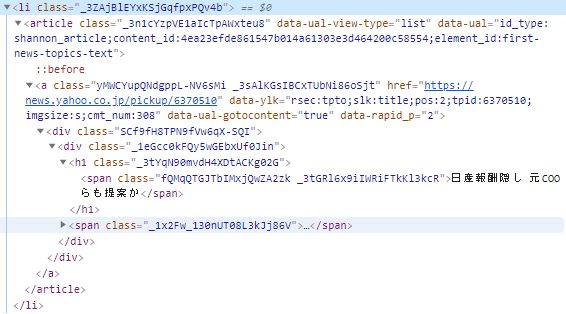
info.append(ele.text.split())先ほど取得したタグの中身を展開してみましょう。実は以下のように多くのタグが設定されています。この中から見えているテキスト部分のみを取得する必要があります。
BeautifulSoupで取得した文字列にはタグも全て含まれてしまっています。このタグ部分を削除するために、split()を使っています。splitは何も指定しないと文字列の前後から空白やタグ、改行などを一切消してくれます。この処理により不要なタグ部分を削除し、必要なテキストのみ抽出しています。
実行結果、リスト型で取得
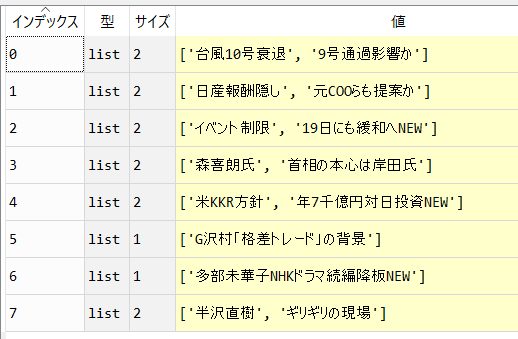
こちらが実行結果です。リスト型で取得することができました。後は必要に応じてアウトプットしましょう。


コメント