

こんにちは、しらすです。
前回はとりあえず動く機械学習アプリを作成してみました。前回の状態でもデータによっては96%程度と割といい精度で分類できるモデルを作成することができました。

識別精度が96%もあれば十分すぎる精度でしょう。しかし多くの問題ではこれほど高い数値が最初から出ることはありません。そのため実問題で精度を上げるためには様々な工夫をしていく必要があります。
まずは第2回ということで「Hyper parameter」と呼ばれるパラメータを適切に設定する方法について説明したいと思います。
Hyper parameter とは?
Hyper parameterとは、学習によって変化しないパラメータです。学習を開始するときに入力するパラメータで、学習のための基本的なフレーム設定のようなものです。手法によって設定すべきHyper parameterは様々異なります。
学習されても変わらないので、この値をどれだけ適切に設定できるかで識別性能が大きく変わります。精魂込めて学習させたモデルが日の目を見るかどうかもこの設定次第というわです。
Hyper parameterを適切に設定するには!?
Hyper parameterは経験に任せて設定することももちろん可能です。ただ、未経験の人や手法の理解が浅い、手法を理解していても適用する問題が複雑、などなど現実の問題に対して知識と経験だけで適切に行うのは大変困難です。
じゃあどうするの?
ということですが、もっとも簡単な手法はグリッドサーチを使うことです。仰々しい名前ですが中身は単純で「範囲を決めて総当たり」です。
実際に最適な値を探してみる
今回は二分岐モデルのRandom forestという手法についてHyper parameterの最適な値を探していきたいと思います。
入力データとして、UCIの機械学習用データリストの中から白ワインの品質分類データを使用します。以下のPythonコードでデータのダウンロードとCSVへの保存が可能です。
from urllib.request import urlretrieve
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv"
savepath = "winequality-white.csv"
urlretrieve(url, savepath)Quality(品質)を3~9までで分類されたデータです。データ数に偏りがあるため、今回は以下のように品質を0~2の3段階まで圧縮して使用します。
#data re-laveling
newlist = []
for v in list(y):
if v <= 4:
newlist += [0]
elif v >= 7:
newlist += [1]
else:
newlist += [2]
y = newlistデフォルト値での識別性能
Hyper parameterを設定せず全てデフォルトを用いてRandomForestClassifierで学習した場合、識別率は82.4%でした。
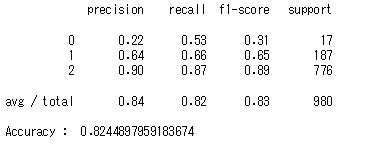
グリッドサーチで算出した最適なHyper parameterでの識別性能
グリッドサーチにより最適なHyper parameterを算出して学習することで精度向上を狙います。
#Set grid search condition
grid_param = [{"n_estimators": [20,50,100],
"criterion" : ["gini", "entropy"],
"max_depth" : [None,3,5,7],
"random_state": [0,10,20,30]
}]
#Select algorizm
kfold_cv = KFold(n_splits=5, shuffle=True)
clf = GridSearchCV(RandomForestClassifier(), grid_param, cv=kfold_cv)
#data learning
clf.fit(x_train, y_train)
print("Best parameter = ", clf.best_estimator_)結果、以下のように最適なHyper parameterを得ることができました。

このHyper parameterを使って計算すると84.4%まで精度が上がりました(約2.0%の向上)。微小ではありますが改善。グリッドサーチの区間を適切に設定すればさらに精度があがりそうです。
まとめ
今回はRandom Forestのハイパーパラメータの決め方について、グリッドサーチという手法を使って実装しました。scikit-learnではライブラリがすでに用意されており、非常に簡単に実装できることがわかりました。
半面、グリッドサーチで使用するHyper parameterの範囲をあらかじめ決める必要があること、組み合わせで検証するので検証数によっては検証時間が指数的に伸びてしまうことがわかりました。特にHyper parameterの範囲を決めておかなければいけない点は、手法について理解がないと適切な範囲を設定できないため思ったような改善効果が得られません。また、たとえ手法を理解していても問題が未知数の場合は設定が難しいという、グリッドサーチを実施する目的そのものが問題点として残っていることがわかりました。
これ以外にもランダムサーチといった手法があります。知識が足りない、未知の問題などの場合はランダムサーチで当たりをつけ、グリッドサーチで最適化するといった方法がよさそうです。
次回はOpenCVを使った手書き文字認識をやっていこうと思います。ご覧いただきありがとうございました。
参考 : Random Forestのハイパーパラメータ一覧
| ハイパーパラメータ | 選択肢 | default |
|---|---|---|
| n_estimators | int型 | 10 |
| criterion | gini、entropy | gini |
| max_depth | int型 or None | None |
| min_samples_split | int、float型 | 2 |
| min_samples_leaf | int、float型 | 1 |
| min_weight_fraction_leaf | float型 | 0 |
| max_features | int、float型、None、auto、sqrt、log2 | auto |
| max_leaf_nodes | int型 or None | None |
| min_impurity_decrease | float型 | 0 |
| min_impurity_split | float型 | 1e-7 |
| bootstrap | bool型 | True |
| oob_score | bool型 | False |
| n_jobs | int型 or None | None |
| random_state | int型、RandomState instance or None | None |
| verbose | int型 | 0 |
| warm_start | bool型 | False |
| class_weight | 辞書型、balanced、balanced_subsample or None | None |



コメント