
こんにちは、しらすです。
Pythonでデータ処理を始めましたが、基本的に使うコマンドが共通なので、メモとして残しておきたいと思います。
データはKaggleからTitanicのTrainingデータを使うことにします。
ライブラリ読み込み
import numpy as np # 計算系
import pandas as pd # データ処理系
import matplotlib.pyplot as plt # 表示系データ読み書き
csvからデータを読み込み
df = pd.read_csv('data/test.csv')
df = pd.read_csv('data/test.csv', index_col=[4]) # indexにする列を指定して読み込みcsvにデータ書き出し
df.to_csv("output.csv") # 全て書き出し
df.to_csv("output.csv", columns=['Survived','Name','Ticket','Cabin']) # 指定列のみ書き出し基本情報
データフレームの形状を表示
df.shape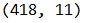
各列のタイトル、データ数、nullの有無、データ型を表示
df.info()
先頭行のIndexを取得
df.columns #全てのIndexを取得
df.select_dtypes(include=[np.number]).columns #数値データのみ
df.select_dtypes(include=[np.object]).columns #オブジェクトデータのみ
指定したオブジェクトデータ列
df["Embarked"].unique() # 指定列の全ユニーク文字列を取得
df['Embarked'].value_counts() # 指定列の全ユニーク文字列の頻度を表示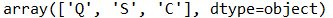

基本統計量の表示
df.describe() # 数値データ列の基本情報(平均、最小、最大)
df.describe(include = 'O') # オブジェクト型データ列の基本情報(各要素数、文字列の種類数、最頻出の文字列)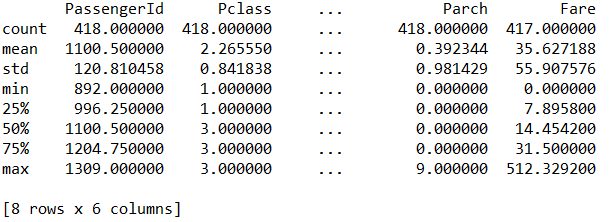

| 項目 | 説明 |
|---|---|
| count | 要素の数 |
| unique | 記載されている文字列の種類数 |
| top | 最頻出の文字列 |
| freq | 最頻出の文字列の出現回数 |
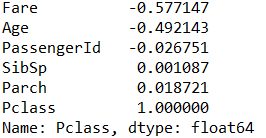
各列の相関係数を表示
df.corr()
df.corr()["Pclass"].sort_values() #指定の列だけ他の列との相関係数を調べてソートして表示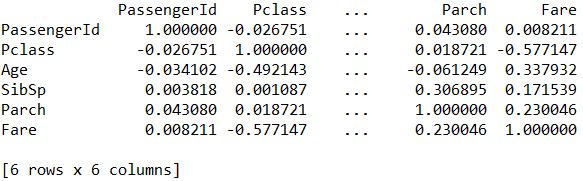
各列のユニーク値の種類を表示
df.apply(lambda x: x.nunique())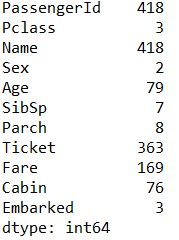
欠損値の数の確認
df.isnull().sum()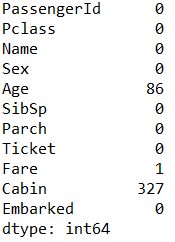
ある列のユニーク文字列別に他の列に対する値の平均を提示
df.groupby('Sex').mean()
ピボットによる集計
df.pivot_table(values='Fare', index='Sex', columns='Embarked', aggfunc='sum')
参考
データ解析の序盤で使える基本的なコマンド集

【Python】データ分析の序盤でよく使う手法メモ - Qiita
Kaggleなどでデータ分析を行う際の探索的データ解析(EDA)の段階で、 データの構造を把握する目的で自分自身がよく使う便利な関数やライブラリをまとめました。 データはKaggleのTitanicのTrainデータを使用します
qiita.com
データをグラフ化する方法

【Python】seabornのグラフを活用したデータ分析の手法メモ - Qiita
はじめに Kaggleなどでデータ分析を行う際の探索的データ解析(EDA)の段階で、 自分自身がよく使うデータのビジュアル化、グラフ化に関する手法をまとめました。 今回はmatplotlibのラッパー、seabornをメインで活用していきます。 参考:
qiita.com
欠損値の処理用のコマンド集

【Python】データ分析における欠損値対応の手法メモ - Qiita
はじめに データ分析において、欠損値の処理は1つの重要なポイントだと思っています。 Kaggleでもスピード重視でこのパートを雑に行うとパフォーマンスが上がりません。 この記事では、コンペ等の分析の際によく使う欠損値の見つけ方と対処方法をざっくりと紹介します。 前処理...
qiita.com


コメント