

こんにちは、しらすです。
25日目です。本日の習得スキルは「欠損値を置き換える」です!
欠損値を置き換えるでできること
pandas.dataframe型で読み込んだデータに対して、欠損値を埋める処理ができます。
使い方
import pandas as pd
csv_input = pd.read_csv("./day24/sample_pandas_normal_nan.csv")
#欠損値を置き換える
result = csv_input.fillna(0)
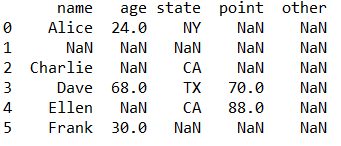
結果
NaNとなっていた欠損値の部分を全て0で置き換えることができました。置き換える値を変えることで任意の値で置き換えることが可能です。
ただ単純に置き換えるだけでなく、列ごとに置き換える値を変えたり、平均値などで置き換えることもできます。
おためし編
列ごとに異なる値で欠損値を置き換える
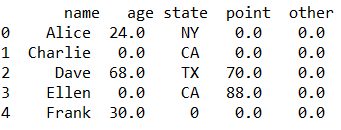
result = csv_input.fillna({'age':0, 'state':'NA', 'point':0,'other':'NA'})
数値の列は0,文字列はNAと入れる
result = csv_input
for col in csv_input:
if csv_input[col].dtype == 'object':
result = result.fillna({col:'NA'})
else:
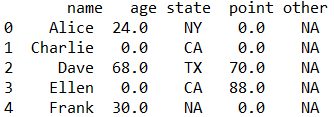
result = result.fillna({col:0})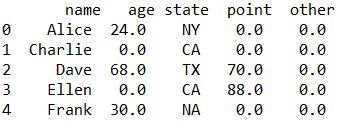
全て欠損値のotherは数値列として判定される様子。

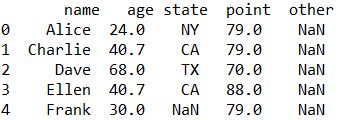
平均値で置き換える(小数点第一位まで)
result = csv_input.fillna(csv_input.mean().round(1))
中央値で置き換える
result = csv_input.fillna(csv_input.median())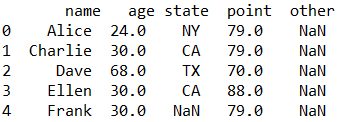
前の値と同じ値で置き換える
result = csv_input.fillna(method = 'ffill')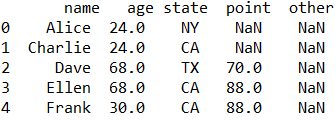
後ろの値と同じ値で置き換える
result = csv_input.fillna(method = 'bfill')
まとめ
一通りの方法を試すことができました。欠損値の除去と合わせればデータクレンジングに大きく寄与することと思われます。
次回は前後の値から平均を入れる方法について確認しておきたいと思います(時系列データを扱う際は前後の値の平均を使用したい)
参考

pandasで欠損値NaNを除外(削除)・置換(穴埋め)・抽出 | note.nkmk.me
例えばCSVファイルをpandasで読み込んだとき、要素が空白だったりすると欠損値だとみなされNaN(Not a Number: 非数)で表される。 欠損値を除外(削除)するにはdropna()メソッド、欠損値を他の値に置換(穴埋め) ...
note.nkmk.me


コメント