

こんにちは、しらすです。
先日AzureのAzure Data Fundamentals (DP-900)の資格を取得したので勉強したことを備忘録として残しておきたいと思います。ネットの情報も少ないので、これからDP-900を受ける方の参考になれば幸いです。
DP-900 試験概要

概要
出題数:49問
試験時間:60分
合格ライン:700 / 1000点
Microsoftの公式ページはこちらからアクセスできます。試験の申込も公式ページから可能です。
難易度
AZ-900と同じ入門レベルですが、データに関する知識を専門的に問う内容になっています。私のようにデータベースに関する基礎知識がない人には少し大変です。ただしAZ-900等をとれている方なら、2日ほどの学習で取得できるレベルだと思います。
評価されるスキル
- コアデータの概念について説明する (15-20%)
- Azure でリレーショナルデータを操作する方法について説明する (25-30%)
- Azure で非リレーショナルデータを操作する方法について説明する (25-30%)
- Azureの分析ワークロードについて説明する (25-30%)
データベースの基本的な知識(DML、DDL、スキーマ関連)やPowerBIに関する設題も多くあり、単にAzureのツールを知っているだけでは難しいです。各ツールで何ができるのか、使いどころやメリットなど一段踏み込んで理解しておく必要があります。
学習用のツール
用意されている専用のトレーニングはMicrosoft公式の以下のもののみです。Udemyにも体系的な講座や試験問題集がないようなので、座学と演習でしっかり知識をつける必要があります。
| Learning Path | Microsoft DP-900のためにMicrosoftが公式で用意してくれているオンライン学習ページ |
| Azure アーキテクチャセンタ | こちらもMicrosoftのオフィシャルガイドです。DP-900向けには「Data」の項目は一通り目を通して理解しておくと安心してテストに臨めます |
私はLearning Pathをメインに学習を実施しました。データベース系の知識が乏しかったため、SQLの基本的な使い方やデータの構造、各種ツールの名前を覚える必要があり、割と大変でした。演習を飛ばして知識だけ覚えるような詰め込みで行ったため、4時間程度で見終わりテストに挑みましたが、結果は上記の通り(あまり知識がついておらずとりあえずどんなツールあるかわかる程度)。
演習は結構めんどくさいですが、一度動かしておくと理解度がぐっと深まるので、しっかり行ってから挑むべきだと思いました。
試験結果
| 受験回数 | 2回 |
| 受験日 |
2021年5月22日(1回目) 2021年5月23日(2回目) |
| 結果 |
650 点 (1回目) 不合格 764 点 (2回目) 合格 |
| 勉強時間 | 4時間 (1回目) + 3時間 (2回目) |
一度目は勉強不足で不合格、次の日に再度勉強してぎりぎり合格しました。
模擬試験が見つけられなかったためぶっつけ本番で挑みましたが、Learning Pathで見たことがない問題も多く玉砕しました。特にデータベースの基本的な知識を問われる部分もあり、苦戦した印象です。2回目は1回目に間違えた部分を中心に効率よく学習できたと思います。
筆者の情報
クラウドは初心者、データベースに関する知識はさわり程度でほぼありません。C,C++を中心に組込系エンジニアとして約7年勤務。趣味でPythonを3年ほど書いており、機械学習と画像処理は専門的な知識があります。
最近クラウド系の勉強をはじめ、先日AZ-900、AI-900、AWSのCloud Practitionerを取得済み。
勉強の際に整理した情報
概要
データの種類
データは構造化データと非構造化データ、半構造化データに分類できます。
| 構造化データ | 2次元の表形式のデータ。リレーショナルデータベースに格納される |
| 半構造化データ | リレーショナル データベースには存在せず、それに対してある程度の構造を持つもの。 たとえば、JavaScript Object Notation (JSON) 形式で保持されているドキュメントなど。 “キー値” ストアや “グラフ” データベースなどに代表され、非リレーショナルデータベースに格納される。 Azure Cosmos DBなど |
| 非構造化データ | オーディオおよびビデオ ファイル、バイナリ データ ファイルなど特定の構造がないデータ。非リレーショナルデータベースに格納される。 Azure Blob(Binaly Large Object) |
トランザクション処理によるデータの処理方法
トランザクションとは小さな個別の作業単位を指します。データベースは、トランザクションの処理中にデータベースの一貫性を維持するために、ACID (原子性、一貫性、分離性、持続性) プロパティに従う必要があります。
| 原子性 | 各トランザクションが 1 つの “ユニット” として扱われ、完全に成功するか、完全に失敗することを保証することです。 |
| 一貫性 | 有効な状態間でのみ、データベース内のデータをトランザクションに取り込むことができるように確保することです。 |
| 分離性 | 複数のトランザクションが同時に実行された場合に、トランザクションが連続して実行された場合と同じ状態にデータベースがなるように確保することです。 |
| 持続性 | トランザクションがいったんコミットされると、停電やクラッシュなどのシステム障害が発生した場合でもコミットされた状態の維持を保証することです。 |
バッチとストリーミングの違い
| バッチ処理 | 一度にまとめて処理すること。夜間やオフピークの時間に一度に処理をまとめて実施することなどが可能。 |
| ストリーミング処理 | データが入るたびに随時処理すること。処理を待つ必要がない。 |
データベース関連業務の役割と責任
| データベース管理者 | ユーザーにアクセス許可を割り当て、データのバックアップ コピーを格納してデータベースを管理し、障害が発生した場合にはデータを復元します |
| データエンジニア | データを操作し、データ クリーニング ルーチンを適用し、ビジネス ルールを特定し、データを有用な情報に変換する上で重要です |
| データアナリスト | データを調査および分析して視覚化やグラフを作成し、組織が情報に基づいた意思決定を行えるようにします |
リレーショナルデータ

Azure Data Services
PaaS カテゴリに分類されるデータベースサービスで、クラウド内で Microsoft によって管理される一連の DBMS です。以下の一般的なリレーショナル データベース管理システムで使用できます。
- Azure SQL Database
- Azure Database for PostgreSQL
- Azure Database for MySQL
- Azure Database for MariaDB
Azure SQL Database
Microsoft によって提供されている PaaS オファリングです。 クラウドにマネージド データベース サーバーを作成し、そのサーバー上にデータベースをデプロイします。Single Database、Elastic Pool、および Managed Instance といった複数のオプションが用意されています。
| Single Database | 単一の SQL Server データベースを迅速に設定および実行できます。 クラウドでデータベース サーバーを作成して実行し、このサーバーを通じてデータベースにアクセスします。 サーバーは Microsoft によって管理されるため、お客様はデータベースを構成し、テーブルを作成し、そこにデータを設定するだけです。 追加の記憶領域、メモリ、または処理能力が必要な場合は、データベースをスケーリングできます |
| Elastic Pool | Single Database に似ていますが、既定で複数のデータベースが同じリソース (メモリ、データ ストレージ領域、処理能力など) をマルチテナントで共有できるという点が異なります。 これらのリソースは “プール” と呼ばれます。 お客様がプールを作成し、お客様のデータベースのみがそのプールを使用できます。 このモデルは、時間の経過と共に変化するリソース要件を持つデータベースがある場合に役立ち、コストを削減できる可能性があります。 Elastic Pool を使用すると、プール内の利用可能なリソースを使用し、処理の完了後にそのリソースを解放することができます。 |
| Managed Instance | Single Database オプションと Elastic Pool オプションでは、SQL Server で使用できる管理機能の一部が制限されます。 Managed Instance では、完全に制御可能な SQL Server のインスタンスがクラウド内で効率的に実行されます。 同じインスタンス上に複数のデータベースをインストールできます。 オンプレミス サーバーの場合と同様に、お客様はこのインスタンスを完全に制御できます。 |
Azure Database for PostgreSQL
ハイブリッドのリレーショナル オブジェクト データベースです。 リレーショナル テーブルにデータを格納できますが、PostgreSQL データベースではカスタム データ型を独自の非リレーショナル プロパティと共に格納することもできます。
Azure Database for MySQL
簡単に使用できるオープンソースのデータベース管理システムとして誕生しました。 これは、Linux、Apache、MySQL、PHP (LAMP) のスタック アプリの主要なオープン ソースのリレーショナル データベースです。 Community、Standard、Enterprise という複数のエディションが提供されています。
Azure Database for MariaDB
新しいデータベース管理システムで、MySQL の初期の開発者たちによって作成されました。 それ以来、パフォーマンスを向上するためにデータベース エンジンが書き直され、最適化されています。 MariaDB は、Oracle Database (人気のある別の商用データベース管理システム) との互換性があります。 MariaDB の注目すべき機能の 1 つは、テンポラル データの組み込みサポートです。 1 つのテーブルにデータの複数のバージョンを保持できるため、アプリケーションは過去のある時点に出現していたデータをクエリできます。
SQLの基本
データ操作言語(DML)
| SELECT | テーブルから行を選択する/読み取る |
| INSERT | テーブルに新しい行を挿入する |
| UPDATE | 既存の行を編集する/更新する |
| DELETE | テーブル内の既存の行を削除する |
データ記述言語(DDL)
| CREATE | データベース内にテーブルやビューなどの新しいオブジェクトを作成します。 |
| ALTER | オブジェクトの構造を変更します。 たとえば、テーブルを変更して新しい列を追加します。 |
| DROP | データベースからオブジェクトを削除します。 |
| RENAME | 既存のオブジェクトの名前を変更します。 |
Azure SQL databaseに対しては以下の方法でクエリを実行できる。
- Azure portal のクエリ エディター
- コマンド ラインまたは Azure Cloud Shell からの
sqlcmdユーティリティ - SQL Server Management Studio
- Azure Data Studio
- SQL Server Data Tools
オンライン分析処理 (OLAP)

大規模なビジネス データベースを編成し、複雑な分析をサポートする技術です。 トランザクション システムに悪影響を及ぼさずに複雑な分析クエリを実行するために、OLAP を使用できます。
オンライン トランザクション処理 (OLTP)
OLTP システムは、組織の日常的な業務でビジネス インタラクションが発生したときに記録し、そのデータに対してクエリを実行して推論する処理をサポートします。
セマンティック モデリング
含まれているデータ要素の意味を説明する概念モデルです。データベース スキーマに対してある程度の抽象化レベルを提供して、ユーザーが基になるデータ構造を知る必要がないようにします。 これにより、エンド ユーザーは、基になるスキーマに対する集計と結合なしで、データのクエリを実行できるようになります。 また、通常は、データのコンテキストと意味を明確にするために、列にわかりやすい名前が付けられます。
分析とビジネス インテリジェンス (OLAP) などの読み取り量が多いシナリオで主に使用されます。
抽出、変換、読み込み (ETL)
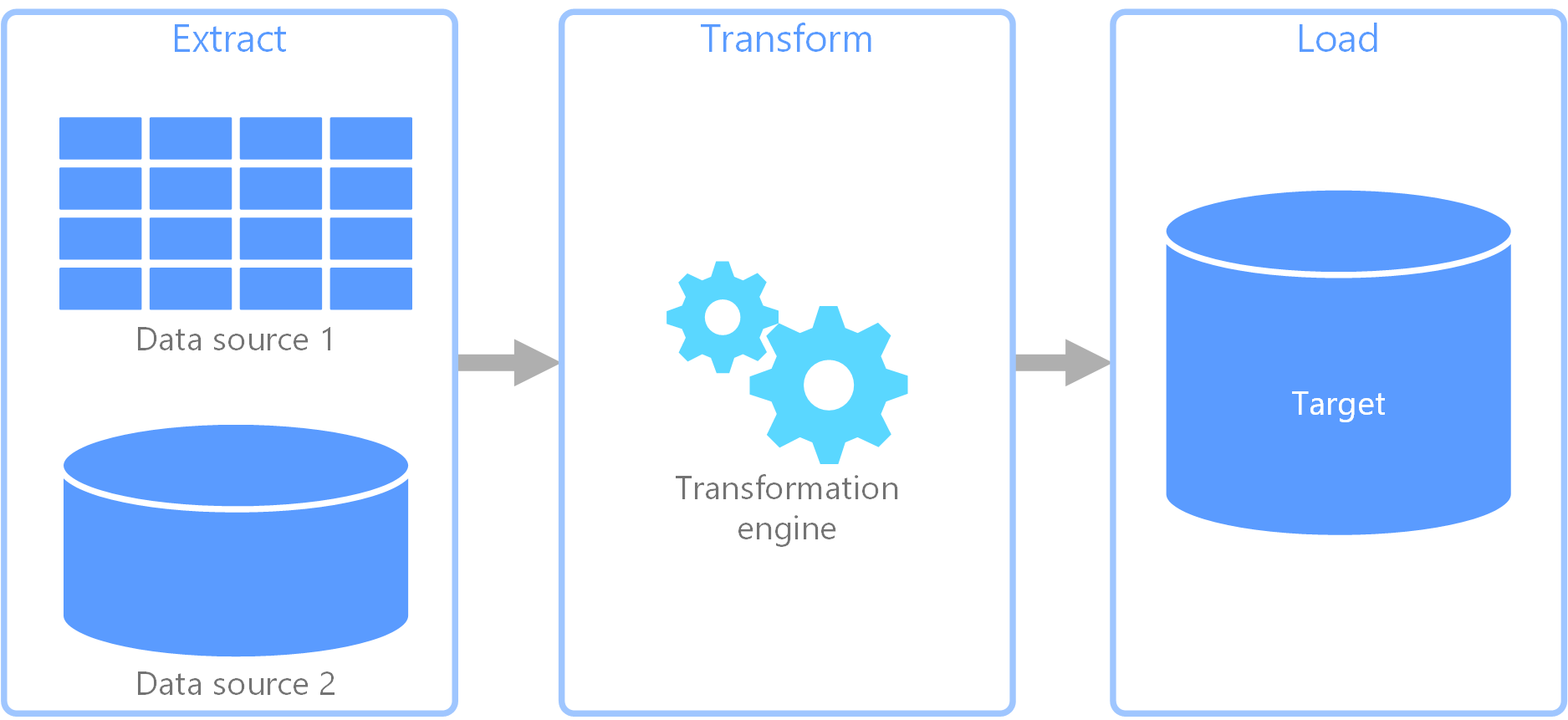
抽出、変換、読み込み (ETL)
さまざまなソースからデータを収集し、ビジネス ルールに従ってデータを変換して、宛先データ ストアに読み込むために使用されるデータ パイプラインです。 ETL の変換作業は特殊なエンジンで行われ、多くの場合、変換されて最終的に宛先に読み込まれるデータの一時的な保持にステージング テーブルを使用します。
抽出、読み込み、変換 (ELT)
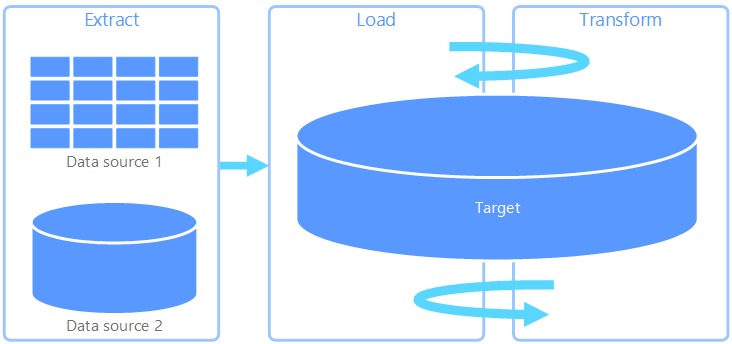
抽出、読み込み、変換 (ELT)
変換が行われる場所だけが ETL と異なります。 ELT パイプラインでは、変換はターゲット データ ストアで行われます。 独立した変換エンジンを使用する代わりに、ターゲット データ ストアの処理機能がデータ変換に使用されます。 これにより、パイプラインから変換エンジンが除去されるためアーキテクチャがシンプルになります。 このアプローチのもう 1 つの利点は、ターゲット データ ストアをスケーリングすると ELT パイプラインのパフォーマンスもスケーリングされることです。
ELT の一般的なユース ケースは、ビッグ データ領域に分類されます。
スキーマ
「構造」と読み替えてよい。ひとまず以下の3つが良くあるスキーマ(ここは素人調べなので間違いがあるかもしれません)
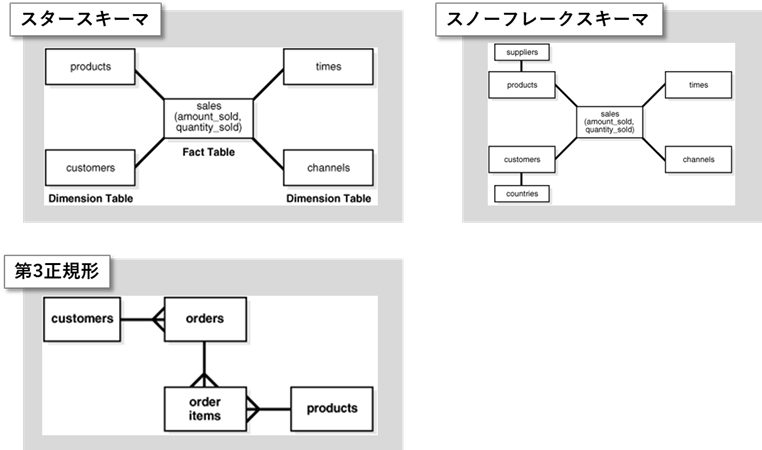
| スタースキーマ | 最も単純なデータ・ウェアハウス・スキーマです。スター・スキーマをエンティティ関連図で表すと、星(スター)のように中央の表から点が放射状に広がっているため、スター・スキーマと呼ばれます。スターの中心は1つの大規模なファクト表で構成されており、スターの先端はディメンション表になっています。 [メリット] – エンド・ユーザーによって分析されるビジネス・エンティティとスキーマ・デザイン間の直接的および直感的マッピングを提供します。 – 一般的なスター・クエリーに、高度に最適化されたパフォーマンスを提供します。 – 多数のビジネス・インテリジェンス・ツールで幅広くサポートされます。 |
| スノーフレークスキーマ | スター・スキーマより複雑なデータ・ウェアハウス・モデルであり、スター・スキーマの一種です。ディメンションが正規化され、冗長性が排除されます。つまり、ディメンション・データは1つの大規模な表ではなく複数の表にグルーピングされます。 [メリット] – ディメンション表が正規化され、冗長性が排除されます |
| 第3正規形 | 正規化を介してデータの冗長性を最小限に抑える古典的なリレーショナル・データベース・モデリング手法です。3NFスキーマでは通常、スター・スキーマと比べると、正規化処理のために表の数が多くなります。 [メリット] – アプリケーションやデータの使用方法の考慮事項とは独立した、中立的なスキーマ設計を提供します。 – スター・スキーマのように正規化度の高いスキーマに比べて、データ変換が少なくて済みます。 |
20 スキーマのモデリング化技法
非リレーショナルデータ
Azure Table Storage
クラウドに保持されているスケーラブルなキー値ストアです。最大で 5 PB のデータを保持できます。
Azure Blob Storage
大量の非構造化データ (BLOB) をクラウドに格納できるサービスです。 以下3つのBLOBサービスを提供しています。
| ブロックBLOB | 各ブロックのサイズは可変で、最大値は 100 MB です。 1 つのブロック BLOB で最大 5 万個のブロックを格納でき、最大サイズは 4.7 TB を超えます。ブロック BLOB は、あまり変更されない不連続で大きなバイナリ オブジェクトを格納するのに最適です。 |
| ページBLOB | ページ BLOB は、固定サイズ 512 バイトのページのコレクションとして編成されます。 ページ BLOB は、ランダムな読み書き操作をサポートするように最適化されています。最大 8 TB のデータを保持できます |
| 追加BLOB | 追加操作をサポートするために最適化されたブロック BLOB です。 追加 BLOB の末尾にのみブロックを追加できます。一つのブロックサイズは最大値は 4 MB です。 追加 BLOB の最大サイズは、195 GB です。 |
アクセス速度に応じてホット/クール/アーカイブという3つのアクセス層が用意されています。
Azure File Storage
クラウド内にファイル共有を作成し、インターネット接続を使用してどこからでもこれらのファイル共有にアクセスできます。1 つのストレージ アカウントで最大 100 TB のデータを共有できます。
HDDに保存するStandardと、SSDに保存するPremiumがある。
Azure Cosmos DB
マルチモデルの NoSQL データベース管理システムです。 Cosmos DB では、データはパーティション分割されたドキュメントのセットとして管理されます。 ドキュメントとは、キーによって識別されるフィールドのコレクションのことです。 各ドキュメントのフィールドは異なる場合があり、フィールドには子ドキュメントが含まれることがあります。 多くのドキュメント データベースでは、ドキュメントの構造を表すために JSON (JavaScript Object Notation) が使用されます。 各ファイルは最大で 2 MB。
Cosmos DB は、高度にスケーラブルなデータベース管理システムです。 Cosmos DB によって、コンテナーにパーティション用の領域が自動的に割り当てられ、各パーティションのサイズは最大で 10 GB まで拡大できます。 インデックスは、自動的に作成されて管理されます。 管理オーバーヘッドは事実上ありません。
可用性を確保するため、すべてのデータベースは 1 つのリージョン内でレプリケートされます。 このレプリケーションは透過的であり、障害が発生したレプリカからのフェールオーバーは自動的に行われます。 Cosmos DB では、99.99% の高可用性が保証されます。
世界中のどこででも、読み取り (インデックス付き) と書き込みの両方に対し、99 パーセンタイルで 10 ミリ秒未満の待機時間が保証されています。
以下の各種APIに対応している。
| SQL API | ドキュメントに対して SQL に似たクエリ言語が提供されており、SELECT ステートメントを使用してドキュメントを識別および取得できます |
| Table API | Azure Table Storage API を使用してドキュメントを格納および取得できます |
| MongoDB API | MongoDB は、独自のプログラム インターフェイスを備えたドキュメント データベースです。MongoDB アプリケーションに変更を加えることなく Cosmos DB データベースに対して実行できます。 |
| Cassandra API | Cassandra は、列ファミリ データベース管理システムです。Cosmos DB 用の Cassandra のようなプログラム インターフェイスが用意されています。 |
| Gremlin API | グラフ データベース インターフェイスが Cosmos DB に実装されます。 Gremlin API を使用すると、そのデータに対してグラフ クエリを実行できます。 |
データストアの種類
ここはLearning Pathに出てきませんでした(当たり前すぎるのか、私が読み飛ばしてしまったのかは不明)が、テストではよく聞かれました。
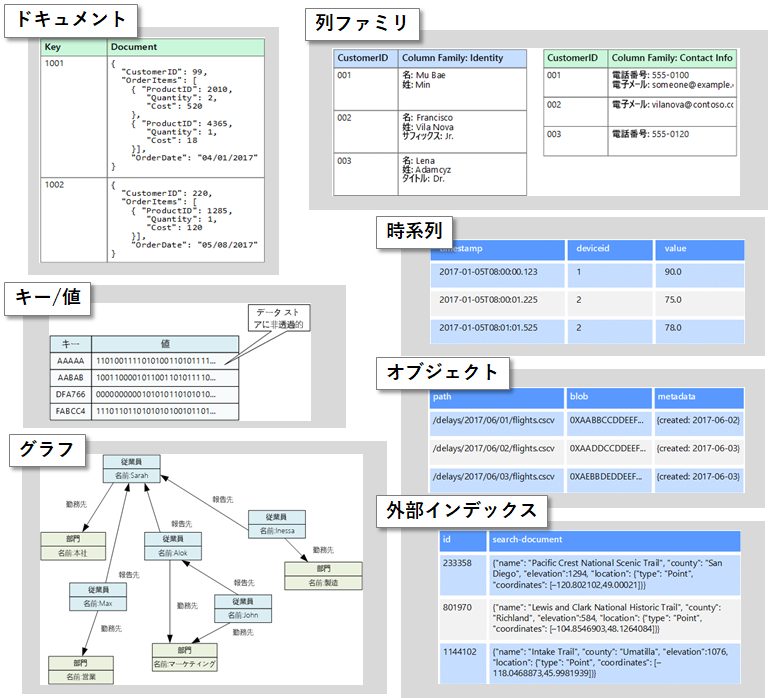
| ドキュメント | ドキュメント と呼ばれるエンティティ内の名前付き文字列フィールドとオブジェクト データ値のセットを管理します。 通常、これらのデータ ストアはデータを JSON ドキュメント形式で格納します。ドキュメントには、エンティティのデータ全体が含まれます |
| 列ファミリ | 列と行にデータを編成します。概念的にはリレーショナルデータベースによく似ています。列ファミリ データベースの真の能力は、データを格納する列指向のアプローチに由来する、スパース データを構造化する非正規化アプローチにあります。 |
| キー/値 | 本質的に大規模なハッシュ テーブルです。 各データ値を一意のキーに関連付けると、キー/値のストアがこのキーを使用し、適切なハッシュ関数を使用してデータを格納します。 ほとんどのキー/値のストアは、簡単なクエリ、挿入、および削除操作のみをサポートしています。 |
| グラフ | ノードとエッジの 2 種類の情報を管理します。 ノードはエンティティを表し、エッジはこれらのエンティティ間のリレーションシップを示します。 ノードもエッジも、そのノードやエッジに関する情報を提供するプロパティを持つことができ、テーブルの列に似ています。 |
| 時系列 | 時間によって編成された一連の値であり、時系列データ ストアはこの種類のデータに合わせて最適化されています。 時系列データ ストアは、通常多数のソースからリアルタイムで大量のデータを収集するため、きわめて大量の書き込みをサポートする必要があります。 |
| オブジェクト | イメージ、テキスト ファイル、ビデオおよびオーディオ ストリーム、大規模アプリケーション データ オブジェクトとドキュメント、仮想マシン ディスク イメージなど、大規模なバイナリ オブジェクトまたは BLOB の格納と取得検索に合わせて最適化されています。 オブジェクトは、格納されているデータ、いくつかのメタデータ、およびオブジェクトにアクセスするための一意の ID で構成されます。 オブジェクト ストアは、個々が非常に大きいファイルをサポートするために設計されています。また、すべてのファイルを管理するために合計サイズの大きなストレージも用意されています。 |
| 外部インデックス | 他のデータ ストアおよびサービスで保持されている情報を検索する機能があります。 外部インデックスは、任意のデータ ストアのセカンダリ インデックスとして機能し、膨大な量のデータにインデックスを付けることができます。また、それらのインデックスにほぼリアルタイムでアクセスできます。 |
データ分析(データウェアハウス)
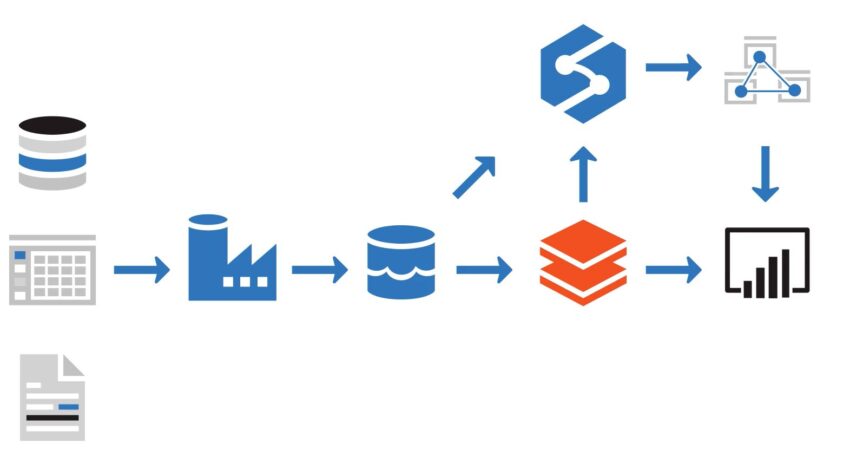
Azure Data Factory
構造化/非構造化データを格納するモジュールです。後続処理のために簡単なフィルタリング/加工処理をパイプラインで視覚的に追加できます。
Azure Data Lake
ペタバイト規模のファイルと数十億個のオブジェクトを保存して分析するためのプラットフォーム。ほぼ無制限のストレージ。分析前の大量のデータを素早く簡単に格納できます。取り込んだデータのステージング層になります。
以下3つの主要要素で構成されています。
- Data Lake Store
- Data Lake Analytics
- HDInsight
Azure Databricks
ビッグ データ処理、ストリーミング、機械学習を実現するために、Azure で実行される Apache Spark 環境。追加データやデータクレンジングを行うことができます。
Azure Synapse Analytics
分析のためにデータを正規化して格納できる。超並列処理 (MPP) アーキテクチャを用いることで、大量のデータを非常に高速に処理するように設計されています。
また、ローカルで読み取って処理したデータをサービス内に格納することで、処理のたびに外部リソースにアクセスする必要がなくして高速化しています。
以下5つの要素で構成されています。
| Synapse SQL プール | Transact-SQLのデータ処理ロジックが記載された場所 PolyBaseを利用して外部データとの接続が可能 |
| Synapse Spark プール | データを処理するために Apache Spark を実行するサーバーのクラスター AIモデルのトレーニングにも利用される |
| Synapse パイプライン | 1 つのタスクを一緒に実行するアクティビティのグループ |
| Synapse Link | このコンポーネントを使用すると、Cosmos DB に接続できる |
| Synapse Studio | データ エンジニアがすべての Synapse Analytics ツールにアクセスできるようにする Web ユーザー インターフェイス |
スキーマとテーブルについても学習しておきましょう。
Azure Synapse Analytics の専用 SQL プールを使用してテーブルを設計する
Azure Analysis Services
入力データの詳細な分析を行いインサイトを創出するモジュール。表形式モデルを構築し、オンライン分析処理 (OLAP) クエリをサポートすることができます。
Azure SQL Database、Azure Synapse Analytics、Azure Data Lake ストア、Azure Cosmos DB など、複数のソースからデータを受け取ることができます。
Azure Synapse Analyticsとサービス面で重複していますが、一般的には以下の用途で2つを組み合わせて使用する場合が多いです。
- Synapse Analytics : 大量データの処理が得意。大量の生データをフィルタリング/変換し、ビジネス価値の高い情報に圧縮するために使用する
- Analysis Services : 複数のデータソースから情報を収集、PowerBIとの連携に強く、見せるデータを作ることが得意。Synapse Analyticsで加工したデータと、他のデータソースからの情報を組み合わせ、最終的なアウトプットを作っていくために使用する
Azure HDInsight
Spark、Hive、MapReduce、HBase、Storm、Kafka、R Server 向けに最適化されたオープン ソース分析クラスターを備え、99.9% の SLA が保証された唯一の完全マネージド クラウド Hadoop サービスです。一連のコンピューターに処理を分散するクラスター モデルが実装されています。
Power BI
Microsoftの標準BIツール。Azure Analysis ServicesやDatabricksからデータを取得し表示することができます。以下3つのツールがあります。
| Power BI Desktop | Windows用のデスクトップアプリケーションです。データ ソースに接続し、レポートを作成します。 |
| Power BI サービス | Power BIレポートの共有と簡単なレポート編集ができるWebサービスです。Power BI Desktopで作成したレポートをPower BI サービスに発行してチーム内で共有します。 |
| Power BI モバイルアプリ | モバイルでレポートを確認するためのモバイルアプリです。レポートを編集することはできず、見るためのツールです。 |
開発ツール
SQLコマンドの発行方法
SQLは以下の5つの方法/ツールで発行できます。
- Azure portal のクエリ エディター
- コマンド ラインまたは Azure Cloud Shell からの
sqlcmdユーティリティ - Azure Data Studio
- SQL Server Management Studio (SSMS)
- SQL Server Data Tools (SSDT)
Azure Data Studio
データ プラットフォームがオンプレミスとクラウドである、データ プロフェッショナルを対象にした、クロスプラットフォーム データベース ツールで、IntelliSense を使用した SQL コード エディター。主にクエリの編集または実行を行っています。
SQL Server Management Studio (SSMS)
データベースのセキュリティやパフォーマンスチューニングなど、総合的な管理を行うためのツール。
SQL Server Data Tools (SSDT)
Visual Studioのアドオンとして搭載されるデータベース管理のためのツール。以下の作業ができる。
- DBのオブジェクトのコーディング支援
- デバッグ機能
- スキーマやデータの比較と同期
- DBのオブジェクトのデプロイ
SQL Server Integration Services (SSIS)
エンタープライズ レベルのデータ統合およびデータ変換ソリューションを構築するためのプラットフォームです。 Integration Services を使用すると、ファイルのコピーやダウンロード、データ ウェアハウスの読み込み、データのクリーニングとマイニング、SQL Server のオブジェクトやデータの管理などにより、複雑なビジネスの問題を解決できます。
Integration Services では、XML データ ファイル、フラット ファイル、リレーショナル データ ソースなど、さまざまなソースのデータを抽出および変換して、1 つ以上のターゲットに読み込むことができます。
SQL Server Integration Services
Azure Data Explorer
アプリケーション、Web サイト、IoT デバイスなどからの大量のデータ ストリーミングをリアルタイムに分析するためのフル マネージドのデータ分析サービスです。さまざまな質問を送ってオンザフライでデータを繰り返し探査することにより、製品の改良、カスタマー エクスペリエンスの強化、デバイスの監視、操作の向上を実現できます。データのパターン、異常、および傾向を迅速に特定することができます。新たな質問を試して、数分で回答を得ることができます。最適化された価格体系を活用して、必要な数だけクエリを実行してください。
Azure Data Explorer
参考



コメント