

こんにちは、しらすです。
Pythonでの機械学習を勉強中です。ですが、結局本とかに載っているデータを持ってきて、書いてあるやり方に沿って進めているだけという状況で、あまり自分で分析しよー!ということができていませんでした。
そんなとき、ネットサーフィンしていたらとても面白そうなものが!!

【Python】pandasで日経平均の株価データをスクレイピングする
Pythonで株価データを取得する今回はPythonで日経平均株価を取得していきたいと思います。環境はWin10・Ancondaを使用しています。anaconda?jupyter?という人は以下の記事を参照してください。この2つはpytho
tkstock.site
昨今のコロナの影響もあり、株式市場は大打撃を受けているこの頃。AIを使った分析でどうなるのかとても興味があったので(この延長線で予測アプリとか作ればもうかるかも!?←頭いい人がすでに作っているがw)最近学んだWebスクレイピングとPythonの機械学習ライブラリ「Scikit-learn」を使って予測モデルを作ってみました!
前日から株価が上がったかどうかを予測
1950年1月1日の日経平均から2020年5月21日までのデータを取得し、過去7日間のデータを基に8日目の株価が前日より上がるか下がるかを学習、評価しました。
実際のコード
import pandas_datareader.data as web
import pandas as pd
import datetime
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
#Get Nikkei stock average from web
nikkei = web.DataReader("NIKKEI225", "fred", "1950/1/1")
plt.plot(nikkei)
#Transform to Logarithmic rate of return
nikkei['log_change']=np.log(nikkei['NIKKEI225'])-np.log(nikkei['NIKKEI225'].shift(1))
nikkei2=nikkei['log_change'].values
#Reshape for matrix with 7days data + 8th-day data as one line
term = 7
pricedata = []
length=len(nikkei2)
for i in range(0,length-term-1):
pricedata.append(nikkei2[i:i+term+1])
df=pd.DataFrame(np.array(pricedata).reshape(-1,8))
df.columns = ['1st_day', '2nd_day', '3rd_day','4th_day', '5th_day', '6th_day','7th_day','8th_day_pred']
#Delete N/A data
df=df.dropna()
df=df.reset_index(drop=True)
#Transfrom to boolian based on the increase/decrease from 1 day before
for i in range(1,len(df)):
if df['8th_day_pred'][i]>0:
df['8th_day_pred'][i]=1
elif df['8th_day_pred'][i]<0:
df['8th_day_pred'][i]=0
#Separate conditions and answer
x=np.array(df.drop(['8th_day_pred'],axis=1))
y=np.array(df['8th_day_pred'], dtype=np.int16)
#Separate train data and test data
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0,shuffle=False)
#Set grid search condition
grid_param = [{"n_estimators": [50,100],
"max_depth" : [None,5],
}]
#Set cross validation condition
kfold_cv = KFold(n_splits=5, shuffle=True)
#Set algorizm
clf = GridSearchCV(RandomForestClassifier(), grid_param, cv=kfold_cv)
#Machine learning
clf.fit(x_train, y_train)
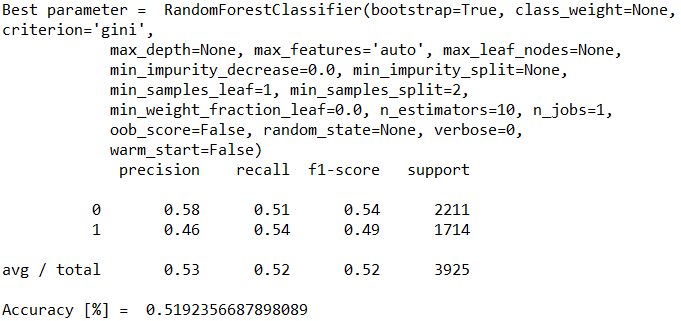
print("Best parameter = ", clf.best_estimator_)
#Prediction
y_pred = clf.predict(x_test)
#output
print(classification_report(y_pred, y_test))
print("Accuracy [%] = " , accuracy_score(y_test, y_pred))
print(datetime.datetime.now().strftime('%Y.%m.%d. %H:%M:%S'), " Analysis have done")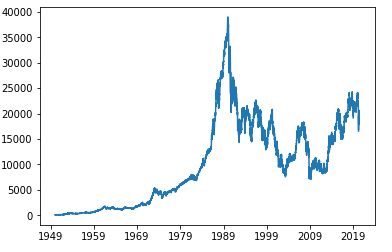
結果
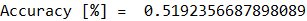
時系列データの機械学習方法を学ぶことができました。無事予測するところまでいきましたが、精度は52%。。。。コイントスレベル!運ですww こいつに任せたら確実に破産なので、次回はもう少し精度を上げる工夫を入れていきたいと思います!
また、株価を学習するときは株価そのままではなく対数収益率に変換してから学習する必要があることがわかり勉強になりました。入門としては十分楽しんで理解を進めることができたかな。

コメント