
こんにちは、しらすです。
深層学習の書籍を購入して読んでいるときに、ふとなぜそのパラメータや閾値が選ばれたのか?という疑問が浮かんできました(たぶん私のような初心者はこの辺が気になる機会が一度はあるはず)。ふとネットで調べたらとても興味深い話を見つけたので記録しておきたいと思います。
実用的に用いる機械学習には、結果に至るまでの説明性がなければいけない、という議論はよく話されるがと思います。これまでの簡易なモデルであれば、結果は人がわかるような理由がつけられる場合が多くありました。しかし、画像処理を先頭に近年の高等なモデルでは人間の理解できない結果をもたらす場合があります。特に深層学習(Deep learning)の登場以来その傾向は加速し、昨今精度が高いアルゴリズムは結果だけでなく過程ですら人間が理解できる場合のほうが少なくなってしまいました。
昨今流行りの「自動運転」といった分野はこのあおりを特に強く受けております。自動運転では、「機械が間違ったときに人がケガをする、亡くなる」といった重大な事故に発展するからです。そのため、処理の過程には説明性が強く求められ、説明性がないものについてはどんなに精度がよくても採用されることは稀です。
片や機械学習系の技術を実装する際は、「なぜそうなったかがわからない」というもでるのほうが往々にして精度が高い、というパラドックスに陥っている印象があります。
精度の高さと説明性は反比例!?
そんなもやもやを感じていたのですが、以下の記事を読んでとてもすっきりしました。
個人的にとても納得を得た一文が以下です。
結局Deep諸系統のモデルは「ヒトが直感的には理解できないような構造の学習データに対しても多層モデルによって柔軟に対応して優れた当てはまりを実現できる」ということなので、そもそもの原理的な出発点として「ヒトの理解を超えたところで威力を発揮する」ものなのでしょう。
機械学習の説明可能性(解釈性)という迷宮
この「ヒトが直感的に理解できない構造」というのがキモということです。
感じられる細かさや関連性を記憶できる量というのは限界があります。もし際限のない量を記憶できるのなら、また、もし数pixel単位の違いを認識することができれば、 もしかしたらそこに新しい関係性を感じることができるかもしれません。 しかし、人には限界があります。
もちろんコンピュータにも限界はありますが、当然人よりも大量に情報を記憶/処理することが可能です。そのため、人では感じることができない関連性も、コンピュータであれば感じることができるということであり、これを以って精度を高めているということだと思います。
以下の言葉は少し皮肉ですが、結局は人の理解できる、ということを念頭に置いてしまうとどうしてもモデルは「廉価」するしかありません。
「説明性」を論じること自体が無駄なのか
簡単に分離できるデータなら分離の過程など必要ないと思われる。そのため、 問題が複雑な場合にようやく説明性という話が出てくる。 しかし、複雑なデータはそもそも複雑なので高度なモデルが必要になり、結果的に説明性は失われてしまう。
結局、説明性は問題の複雑さにのみ依存し、問題が複雑でも簡単でも説明性は議論する余地がないのかもしれない。(以下引用)
線形分離可能パターンのデータに対してはそもそも線形モデルのようなヒトが理解しやすいモデルがあるから「説明可能性」は問題にならないし、一方で線形分離不可能(極度に)パターンのデータに対してはヒトが理解しやすいモデルは存在し得ないので同様に「説明可能性」を論じるだけ無駄である、ということになります。
機械学習の説明可能性(解釈性)という迷宮
上記の記事の中で引用されていた論文で、説明性(Interpretability)と精度(Accuracy)についての対比図もとてもわかりやすかったので、以下に引用しておきたいと思います。

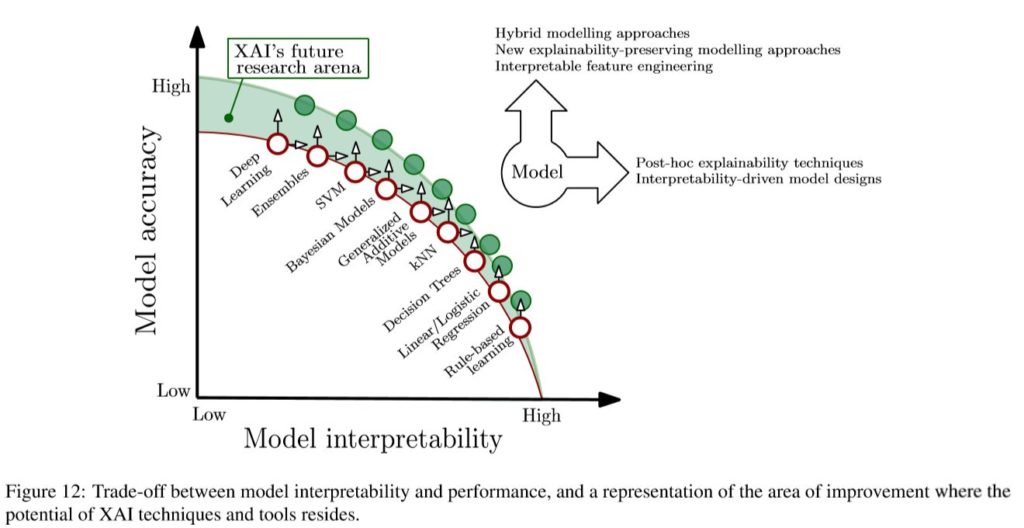
モデルの精度としては「ルールベース<線形モデル<決定木<……<SVM<アンサンブル<Deep Learning」だと言っていますが、モデルの解釈性としてはその真逆で「ルールベース>線形モデル>決定木>……>SVM>アンサンブル>Deep Learning」だと言っているわけです。これはbias-variance tradeoffに次ぐもう一つのtradeoffとして掲げても良いのではないかと思うくらいです(笑)。
機械学習の説明可能性(解釈性)という迷宮


コメント